Understanding Operator's Behavior on the Internet
Operator is a computer-using agent developed by OpenAI, a type of AI system that uses computers for you. It has become one of the offerings of their ChatGPT product, where the assistant would spin up a virtual Chrome browser in the virtualized cloud environment, and perform various tasks ranging from booking tickets and tables to conducting research.
An agent is a kind of system that can perceive the environment, make decisions, and act on those decisions. The capability for an agent to control a computer has become very prevalent over the past few months, as foundation models have become much more capable of reasoning about images, text, and the web, creating complex plans, and acting on them, especially on a computer.
There are profound implications to the Internet when these "agents" are massively deployed, and the trends suggest they are. Not enough effort has been made to understand their behaviors, and the little efforts we do are clouded in confusion and misunderstandings.
Often times, the following three concepts are discussed interchangeably with each other: AI scraping/crawling (bots), AI search engine/indexing, and (computer-using) AI agents.
Granted the boundaries between the concepts are not very fundamentally clear, but we don't live in a vacuum either: important narratives are being floated around when discussing policy-adjacent issues surrounding these technologies.
AI, in their various stages of the development lifecycle, need to access data. And many of the data they access is owned by some people. This makes the method by which they access such data, in various stages, contentious issues. Some observations are insightful but incomplete, others are woefully wrong.
There are a few very important misconceptions that I hope to clear up in future essays, but let's start with something much simpler. For continuity I will list all of them below as the root of the misconceptions also relate to each other:
1. Internet-scale scraping operations are still a top priority of data teams of AI chatbot developers
Untrue for a variety of reasons. Won't expand but I will list below:
- Limited capability gain as we no longer dreadfully need a better base model
- Proliferation of open-weight models imply that it is both legally risky and capitally intensive to train your own base model
- Rising importance of human data, preferences, behaviors, that are collected from paid offshore annotators or harvested from users
- The wonderful work from CommonCrawl (CC) in supporting academic research, where the focus now turns to better filtering heuristics on CC slices
2. Large-scale scraping operations are not being done at all
Untrue because of:
- The observed gap between open-source models from which we know more definitively than not its full training data and the rest of the models. Note that DeepSeek and Llama herd, which are open-weight but not open-source models, fall to the latter category as we do not know what data they are trained on.
- The anecdotal evidence of massive targeted scraping by AI chatbot developers.
3. Large-scale scraping operations can be tracked easily
Truer in recent years due to regulatory pressure, but definitely untrue before the rise of foundation models. The entire mechanism from which current tracking of scrapers is built on, `robots.txt`, has no enforcing mechanism whatsoever: it requires the bot to self-identify. This identity can be extremely easily spoofed, thanks to a class of technologies called residential proxy pools, which are also formed using non-traditional means. A frontier AI chatbot developer nowadays may be more reluctant to not self-identify as such an operation can be easily leaked and cause negative press, but from a game-theoretic perspective, there is virtually no cost to not self-identify.4. AI chatbots, once trained, do not need access to data anymore
Untrue due to the need to provide up-to-date information. In fact, there are various startups providing up to date information by scraping on behalf of AI chatbot developers, isolating the risk.... which brings us to the narrow focus of this post:
- Computer-using agents' behaviors can be easily tracked.
A popular, appearing-on-multiple-media service called Dark Visitors specifically claims that they can "Track the AI agents browsing your website", prominently featuring Operator:
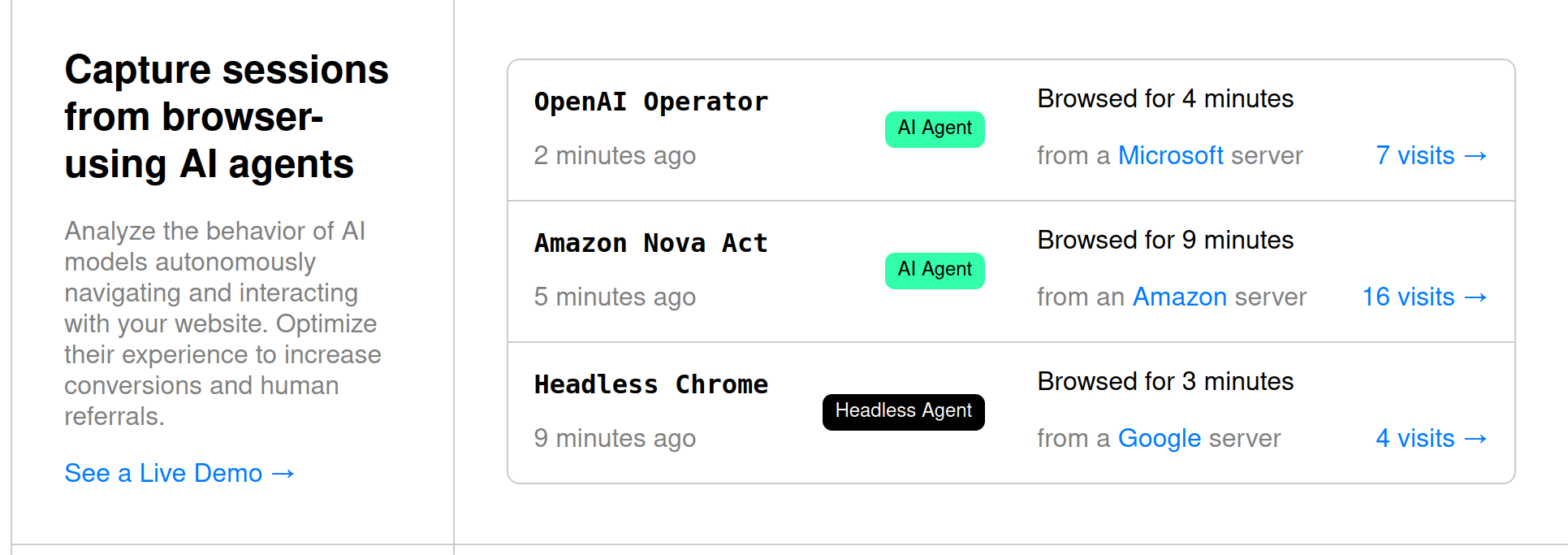
We now show that this claim is either extremely naive about the nature of computer-using agents, or an intentional understatement about the complexity in their behaviors.
Let's break down what Dark Visitors imply in their offerings:
- Operator's traffic originates from a Microsoft server, and whoever runs the site has the capability to know that
- Operator self-identifies as
Operatorin their user-agent header
From first principles, these claims look sketchy for the following reasons:
- Computer-using agents are not usually considered as a scraper by both the developers themselves (Google, OpenAI, Amazon) and whoever decides to block them (Cloudflare, Arkose). The fact that one may be able to definitively know if a request originates from, say, Google's server is because Google publishes them. OpenAI does not consider Operator to be a bot at the moment of writing either.
- Computer-using agents use computers just like humans do - if you saw Operator's demo, you can see that the AI is using the graphical interface directly, as opposed to programmatic interactions via APIs. If OpenAI does nothing, the signature of the client would be that of a normal browser, not
Operator.
In fact, as Operator is a generally available consumer product, we can verify the claims easily! The idea is that we can host a website ourselves, with some structure (e.g. multiple posts within a blog), and ask Operator to visit our website to do some nontrivial task. By closely observing what Operator is doing, which we can, via injecting Javascript to capture mouse moves and clicks and additional telemetry to the backend, we can definitively observe both the user-agent header and the origin IP. Here's what it looks like:
(Update 12/25/25: OpenAI has deprecated Operator recordings completely.)
Now, for the logs:
{'timestamp': '2025-05-26T22:40:36.450947', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'page_load', 'event_data': {'url': '.../', 'referrer': '', 'screenWidth': 1280, 'screenHeight': 960, 'timestamp': '2025-05-27T02:40:36.382Z'}}
{'timestamp': '2025-05-26T22:40:41.825874', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'click', 'event_data': {'x': 442, 'y': 340, 'target_tag': 'A', 'target_id': '', 'target_class': ''}}
{'timestamp': '2025-05-26T22:40:41.898346', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'event_batch', 'event_data': {'events': [{'type': 'mouse_move', 'data': {'x': 442, 'y': 340}, 'timestamp': '2025-05-27T02:40:41.647Z'}]}}
{'timestamp': '2025-05-26T22:40:42.053582', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'visibility_change', 'event_data': {'visibilityState': 'hidden', 'timestamp': '2025-05-27T02:40:41.963Z'}}
{'timestamp': '2025-05-26T22:40:42.317075', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'page_load', 'event_data': {'url': '.../post/1', 'referrer': '.../', 'screenWidth': 1280, 'screenHeight': 960, 'timestamp': '2025-05-27T02:40:42.221Z'}}
{'timestamp': '2025-05-26T22:40:49.593019', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'click', 'event_data': {'x': 202, 'y': 463, 'target_tag': 'A', 'target_id': '', 'target_class': ''}}
{'timestamp': '2025-05-26T22:40:49.611706', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'event_batch', 'event_data': {'events': [{'type': 'mouse_move', 'data': {'x': 202, 'y': 463}, 'timestamp': '2025-05-27T02:40:49.425Z'}]}}
{'timestamp': '2025-05-26T22:40:49.796888', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'visibility_change', 'event_data': {'visibilityState': 'hidden', 'timestamp': '2025-05-27T02:40:49.718Z'}}
{'timestamp': '2025-05-26T22:40:50.047707', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'page_load', 'event_data': {'url': '.../', 'referrer': '.../post/1', 'screenWidth': 1280, 'screenHeight': 960, 'timestamp': '2025-05-27T02:40:49.947Z'}}
{'timestamp': '2025-05-26T22:40:56.758609', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'click', 'event_data': {'x': 457, 'y': 773, 'target_tag': 'A', 'target_id': '', 'target_class': ''}}
{'timestamp': '2025-05-26T22:40:56.761331', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'event_batch', 'event_data': {'events': [{'type': 'mouse_move', 'data': {'x': 457, 'y': 773}, 'timestamp': '2025-05-27T02:40:56.590Z'}]}}
{'timestamp': '2025-05-26T22:40:56.830458', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'visibility_change', 'event_data': {'visibilityState': 'hidden', 'timestamp': '2025-05-27T02:40:56.741Z'}}
{'timestamp': '2025-05-26T22:40:57.017003', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'page_load', 'event_data': {'url': '.../post/3', 'referrer': '.../', 'screenWidth': 1280, 'screenHeight': 960, 'timestamp': '2025-05-27T02:40:56.921Z'}}
{'timestamp': '2025-05-26T22:41:02.845156', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'click', 'event_data': {'x': 107, 'y': 23, 'target_tag': 'A', 'target_id': '', 'target_class': ''}}
{'timestamp': '2025-05-26T22:41:02.845694', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'event_batch', 'event_data': {'events': [{'type': 'mouse_move', 'data': {'x': 107, 'y': 23}, 'timestamp': '2025-05-27T02:41:02.602Z'}]}}
{'timestamp': '2025-05-26T22:41:02.973184', 'ip_address': '2a09:bac5:6588:188c::272:12', 'user_agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36', 'event_type': 'visibility_change', 'event_data': {'visibilityState': 'hidden', 'timestamp': '2025-05-27T02:41:02.896Z'}}
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 is ostensibly not Operator. In fact, it looks just like a normal Chrome user on a Mac.
Now, where is 2a09:bac5:6588:188c::272:12?
ip2location suggests that it is vaguely from Cloudflare, and anecdotal evidence suggests that the range 2a09:bac5 is loosely associated with Cloudflare WARP, an enterprise + prosumer service to securely mask traffic from devices to the rest of the internet. It would make sense why Operator VMs would use WARP, as it conveniently makes the server operator harder to track the origin of the request.
To further confirm our hypothesis, I've asked ChatGPT's o3 model to visit my website via a web search, and here are the server logs:
IP: 52.230.163.45, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /robots.txt - Serving robots.txt
IP: 52.230.163.45, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /
IP: 52.230.163.45, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /robots.txt - Serving robots.txt
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /robots.txt - Serving robots.txt
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /post/1, PostID: 1
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /robots.txt - Serving robots.txt
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /post/3, PostID: 3
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /robots.txt - Serving robots.txt
IP: 52.230.163.46, User-Agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot, Path: /about
Although it did not identify as OAI-SearchBot as it should, it does show up as ChatGPT-User as documented, and we can verify that 52.230.163.45 indeed is a Microsoft server.
The Takeaways
It is an important and hard task to understand the scale, extent, ways, and implications of massive agent deployment on the Internet, and for now, there's an unfortunate discrepancy between the level of sophistication of those who deploy agents and those who study them.
Without fully understanding and reliably detecting agents and bots, regulating them is a pipe dream.
An interesting and exciting direction could be to detect them via behaviors - if you observe the client-side logs, you may see that the agents are extremely goal-oriented and make no extraneous movements. Real humans have a much more "messy" behavior where they wander around, and this could create very strong statistical features that separate a real human from an agent pretending to be one in order to gain access.